基于磁盘的体系结构
数据库中的数据主要存储在磁盘(non-volatile disk,非易失的)中,DBMS主要负责数据在磁盘和内存(non-volatile and volatile storage)中来回移动。
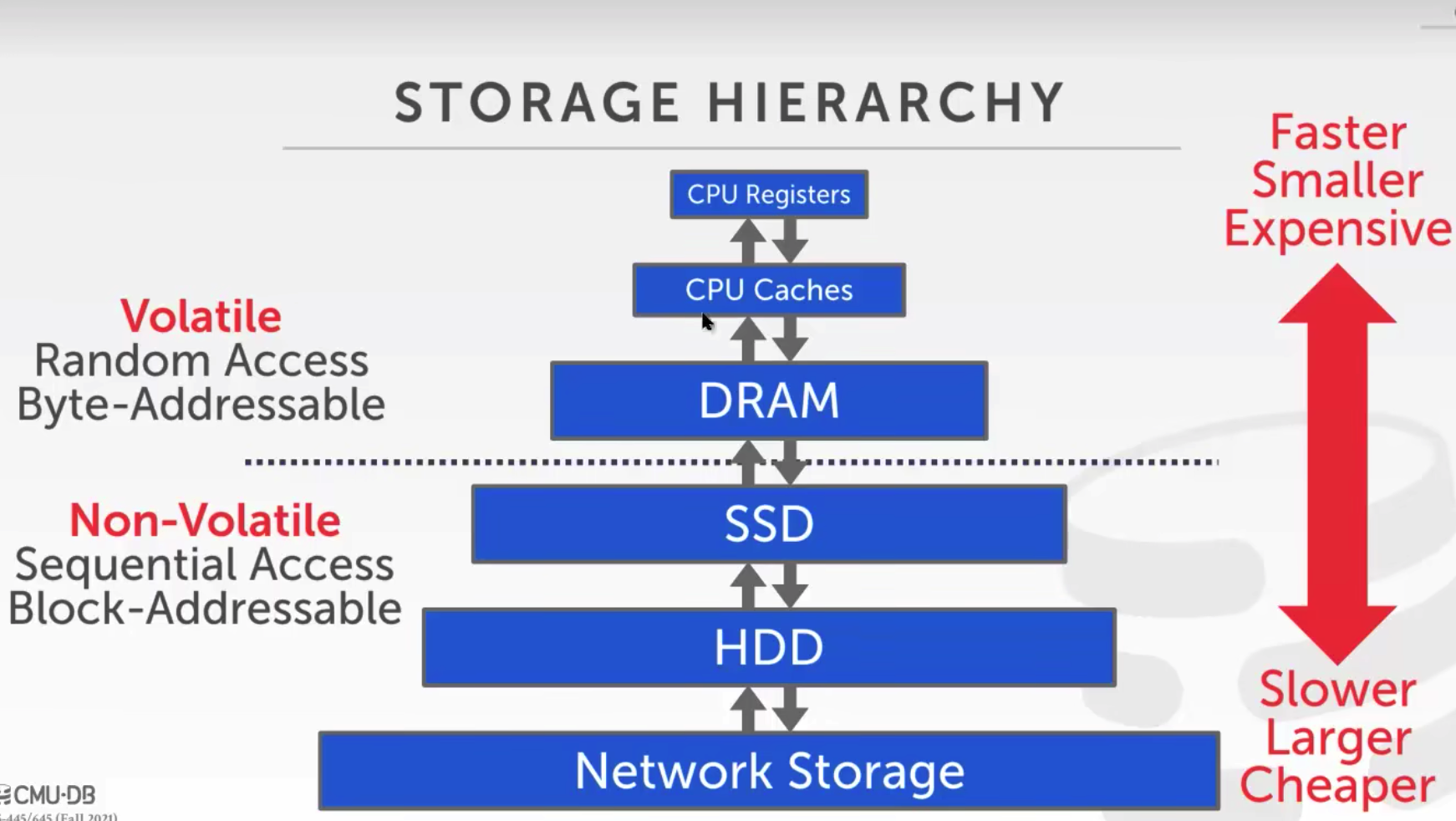
如下图所示,存储体系结构越往上速度越快、容量越小、价格越贵。
内存及往上存储结构支持随机访问,访问地址最小单位是字节,也就说可以读取单个字节数据;ssd及以下存储结构顺序访问,访问地址最小单位是块,存取最小也是一块,比如只想存1B的数据,也需要占一块的空间。
顺序访问与随机访问
通常情况下,在磁盘上,随机访问都比顺序访问要慢的多。因此DBMS希望最大化顺序访问。
也就是说,在写入数据时,应该尽量减少随机写,让数据存储在连续块(block)中。
同时分配多个页面(page)称为区间(extent)。
设计目标
- 应当允许DBMS管理超过内存大小的数据库规模
- 对磁盘的读/写是昂贵的,所以必须小心管理,以避免大的停顿和性能下降。
- 磁盘上的随机访问通常比顺序访问慢得多,所以DBMS希望最大限度地提高顺序访问。
面向磁盘的DBMS设计
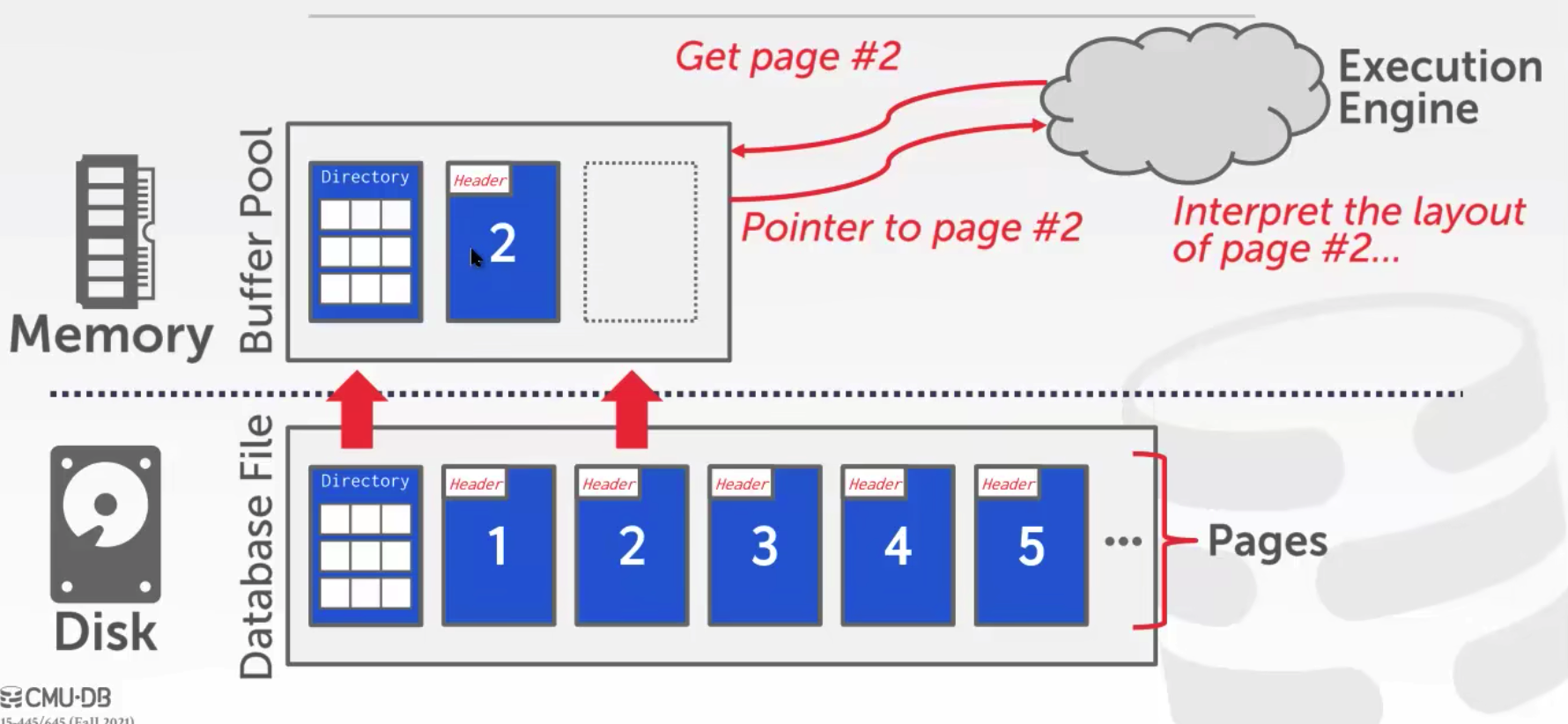
如上图所示,在磁盘中,db里的数据按页存储,有一个directory来标记不同的页分别在哪里,每个页中都有一个header来存放该页的元数据。
上图的例子是想要拿到page#2,先从disk中将directory读到内存的buffer池中,然后根据directory找到page#2,读到buffer池中,执行器疫情再分析page#2。
DBMS应该自己控制存取而不是交给OS
DBMS(几乎)总是想自己控制事情,并能比操作系统做得更好。
- 以正确的顺序将脏页冲到磁盘。
- 专门的预取。
- 缓冲区替换策略。
- 线程/进程调度。
OS并不知道DBMS对数据的操作具体是如何的,遇到缺页的情况,盲目的替换,会导致极差的性能。因此DBMS应该自主控制。
数据库存储需要考虑的两大问题
1. DBMS如何在磁盘上的文件中表示数据库
文件存储 (file storage)
DBMS将数据库作为一个或多个文件存储在磁盘上,通常是一种专有格式。操作系统对这些文件的内容一无所知。
一个页面是一个固定大小的数据块。
- 它可以包含图元、元数据、索引、日志记录…。
- 大多数系统不混合页面类型。
- 有些系统要求一个页面是自解释的,也就说页面中包含描述该页面的信息。
每个页面都有一个唯一的标识符。DBMS使用一个中介层将页面ID映射到物理位置。
在DBMS中的 “页”有三种不同的概念:
- 硬件页(通常为4KB)
- 操作系统页(通常为4KB)
- 数据库页(512B-16KB)
一个硬件页是存储设备可以容纳的最大数据块的数据块,存储设备可以保证故障安全写入的最大数据块。
堆文件是一个无序的页面集合,其tuples是以随机顺序存储的。
- 创建/获取/写入/删除页面
- 还必须支持对所有页面进行迭代。
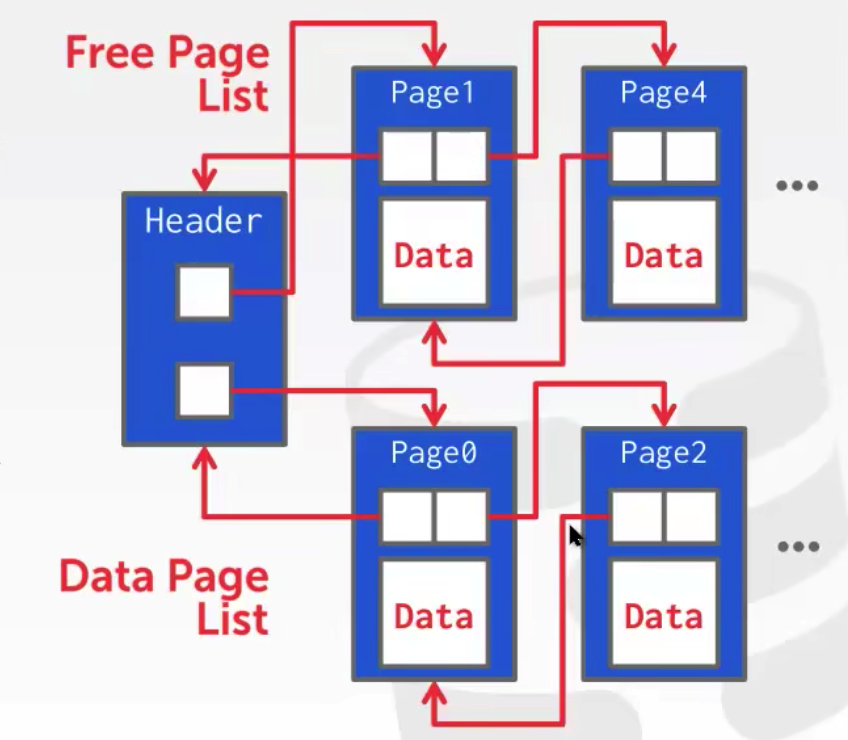
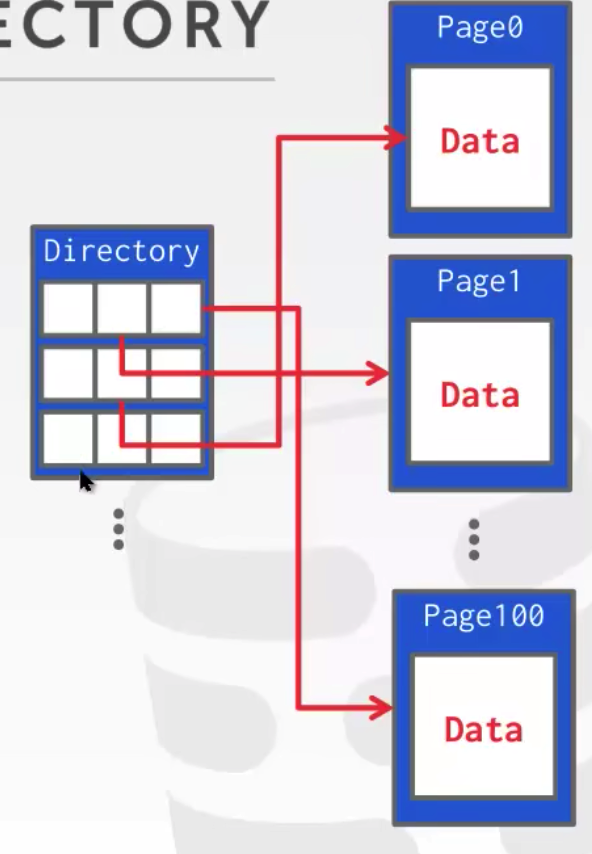
有两种方法来表示堆文件:
链表
页目录
页布局 (page layout)

对于任何页面存储架构,我们需要决定如何组织页面内的数据。
我们假设只是在存储tuple。
有两种方法:
面向元组(常用)
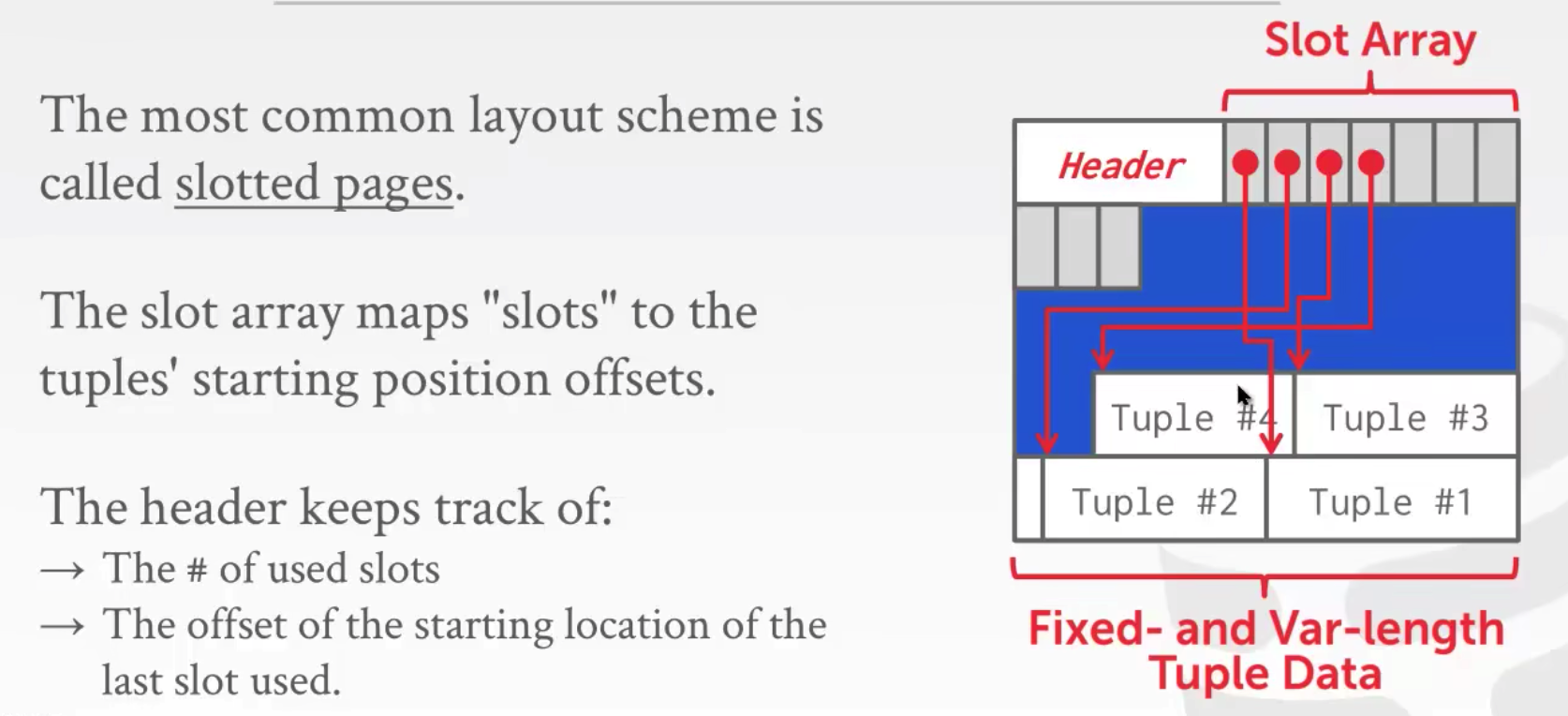
slot从头往后存,实际数据从尾往前存。当删除/新增一个元组时,只需要修改对于的slot指针即可。此外,对于存储碎片问题,可以将存储的tuple迁移到前面去,接着改变相应的slot指针即可,如下图所示。
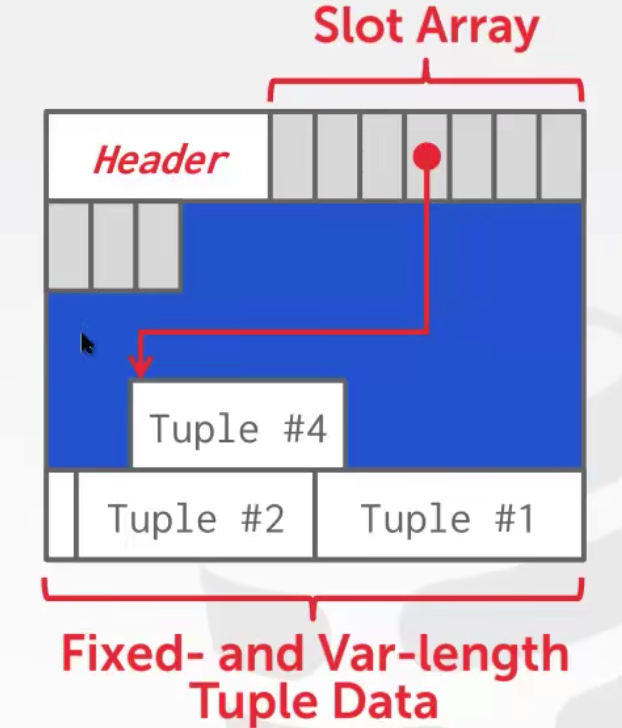
DBMS需要一种方法来跟踪单个tuple。
每个元组都被分配一个唯一的记录标识符。- 最常见的是:page_id offset/slot
- 也可以包含文件位置信息。
日志结构化
DBMS不在页面中存储tuple,而只存储日志记录。
系统将日志记录附加到数据库如何被修改的文件中:- 插入存储整个元组。
- 删除标记了元组的删除。
- 更新只包含被修改的属性的delta。

为了读取一条记录,DBMS向后扫描日志并 “重新创建 “元组以找到它所需要的东西。

也可以构建索引来加速log回放
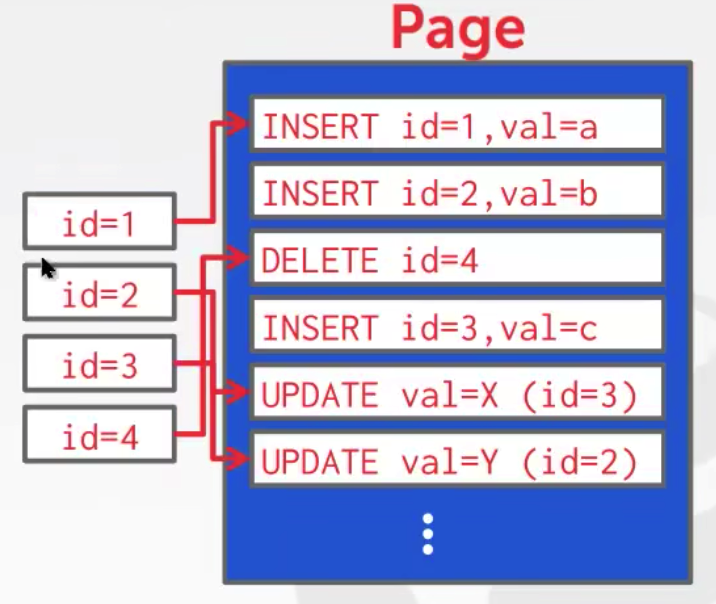
显然,基于日志的数据库非常冗余,所以通常会周期性的压缩数据。上图可以被压缩为如下图所示的状态。
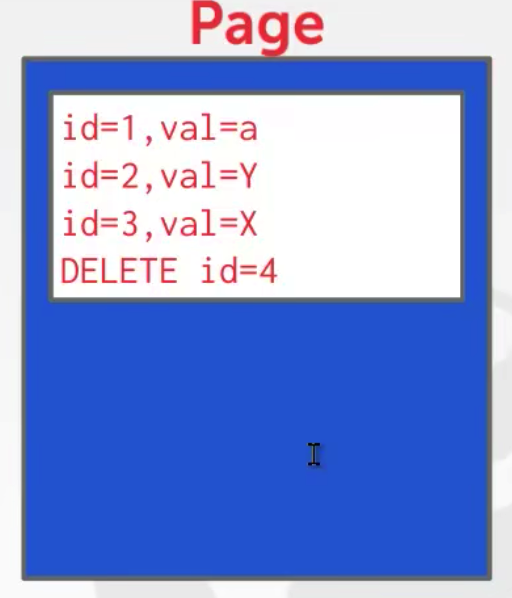
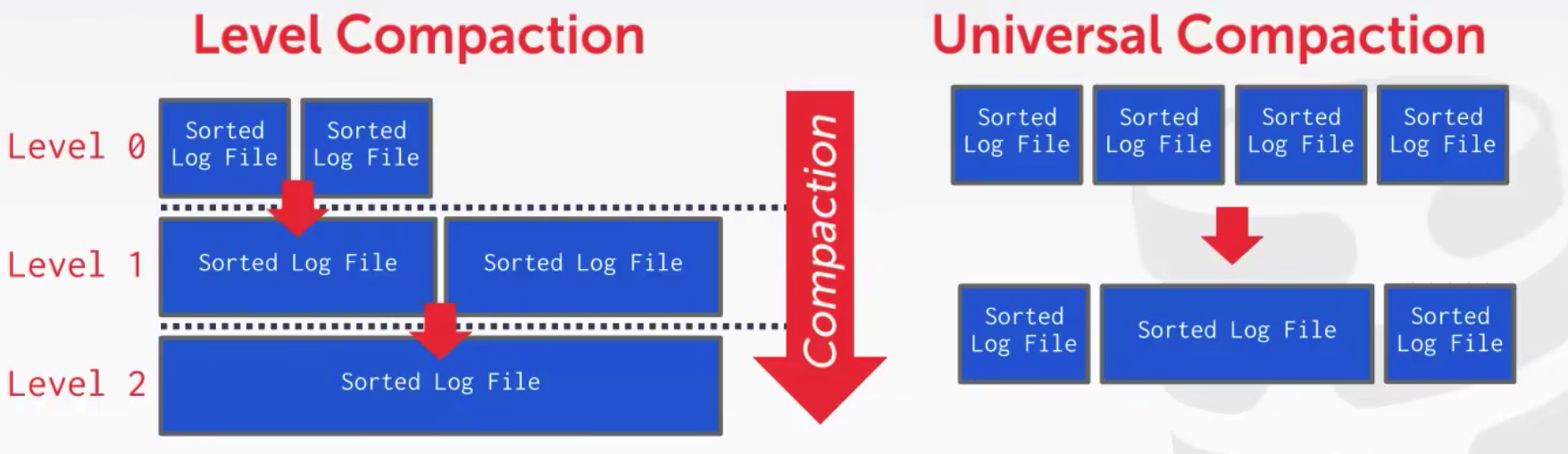
可以看到,上述的压缩中,delete id=4是压缩不了的,因为id=4的创建并不在同一个页中。那么为了解决上述问题,可以采用Level Compaction或Universal Comapction。
元组布局 (tuple layout)
tuple本质上是一组byte序列,DBMS的职责就是将这些bytes解释成属性类型和值。


